原文地址:http://gee.cs.oswego.edu/dl/cpj/jmm.html
声明: 个人英文水平有限,翻译的不对的地方请重拍!
Doug Lee的书:Concurrent Programming In Java的网上地址:http://gee.cs.oswego.edu/dl/cpj/index.html
References: http://www.infoq.com/cn/articles/java-memory-model-1
概述
考虑下面的不带同步的一个小类:
1 | final class SetCheck { |
在一个单纯的顺序执行的语言中,这个方法
check永远不可能返回false。 即使编译器、运行时系统甚至硬件都有可能会用一种违反直觉的方式执行这段代码,这个结果也不会改变。例如,以下的任何一种情形都可能是方法set的执行情况:- 编译器有可能会重排语句的执行顺序,所以:b有可能会在a之前被赋值。如果这个方法是内联的,编译器甚至还有可能会根据其他的语句的执行情况来重排序当前的语句。
- 处理器也可能会重排序这些语句对应的机器码的执行顺序,甚至有可能是同时执行。
- 内存系统(由缓存控制单元管理)可能会对提交给变量对应的内存单元的写操作进行重排序。这些写操作可能会和其他的计算和内存操作重叠。
- 编译器、处理器和内存系统都可能会交错影响这两句代码在机器码层面的执行。 例如,在一个32位的机器上,变量
b的高阶位的字符可能会先被写入,然后是写入变量a,最后才是写入b的低位字符。 - 编译器、处理器和内存系统也可能会将变量对应的内存单元的值放置在某个能让代码有同样执行效果的非内存区域的地方(如CPU寄存器),直到后续的对变量触发校验动作的时刻才会被真正的更新到主存。
在一个单纯的顺序执行的语言中,以上任何一种情况只要代码遵循
as-if-serial顺序执行语义都不会有问题,顺序执行的程序不依赖于代码块内部的底层处理细节,所以他们很好的应对以上任意一种执行情况,这就为编译器和底层系统提供了很好的伸缩性,充分利用这些便利和机会使得过去的十年间计算机的执行速度得到了大幅度的提升。遵循as-if-serial顺序执行语义的所有的这些控制方法使得程序员可以不需要知道底层具体发生了什么,那些从来没有创建过线程的程序员们对这些变化和影响几乎不会有任何的感知。- 但是在并发编程中事情是完全不同的。这种情形下,完全有可能
set是在一个线程中被调用而check是在另一个线程中被执行,也就是说check可能在监听另一个线程中set的执行情况。并且前面说的任何一种控制手段的执行都有可能会导致check返回false,例如下面会描述的细节中,check会读取一个既不是0也不是-1的值给b,而是一个中间的半写入的值。同样的,set方法中的乱序执行可能导致check方法读取到的b是-1然后读取到a还是0。 - 换句话说,不单单是并发执行可能会导致执行的错乱,它们同样也可能会被重排序或为了获得某种形式的优化提升而做一些几乎和源代码没有任何关联的的优化操作。随着编译器和运行时技术的成熟和多核处理器的普及,这种现象也越加的普遍,这对那些只具备单线程顺序执行编程背景并且从来没有接触过底层的所谓的顺序执行代码的程序员来说,程序往往会出现让他们很吃惊的结果。这有可能就是那些狡猾的并发编程错误的根源。
- 在几乎所有可能的情况下,有一种很显然的简单的方式去避免由于代码执行优化机制导致的在并发编程中的复杂的问题,那就是使用同步。 例如,如果
SetCheck类中的两个方法都声明成synchronized,你就可以确认不会有任何的底层的处理细节会影响代码最终的想要的执行结果。 - 但有时候你不能或不想使用同步,又或者也许由于其他人的代码没有使用同步,在这些情形下,你务必要依赖于Java内存模型规定的关于执行结果的最小保证的语义。这个模型允许上面列出的各种的底层操作,但是模型对这些底层操作对执行语义的潜在的影响做了限制,同时提供给程序员一些附加的技术手段去控制这些语义。
- Java内存模型是
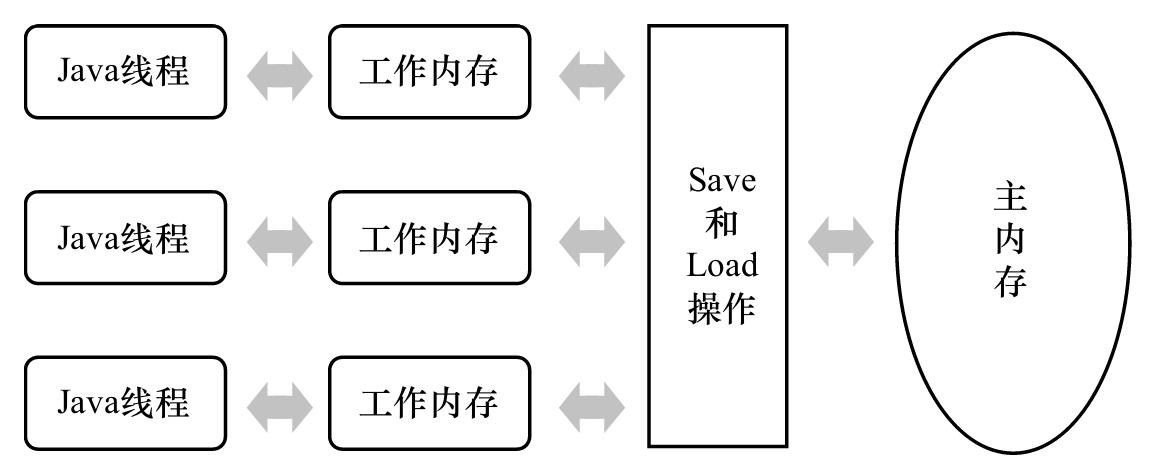
JavaTM语言规范的一部分,主要讲解时在JLS的第17章。 在这里,我们只讨论这个模型基础的使用动机、相关属性和编程影响。 - 我们可以把底层的内存模型假想成如下图的一个理想化的标准的SMP machine图:

- 为便于理解这个模型,我们设想每个线程都运行在一个单独的CPU上。即便在多核的机器上,实际使用中这也是很少见的,但事实上为了让线程占用一些内存模型的初始的属性,这种一个线程一个CPU的匹配方式是合理的且符合这个内存模型的。例如,由于CPU的寄存器不可以别其他的CPU直接访问,这就使得模型就必须允许一个线程感知不到被其他线程操作的的变量的值。但是内存模型的这种影响绝不仅仅限于多核系统,即便在单核CPU上编译器和处理器的一些操作也会产生和多核上一样的担忧和问题。
- 这个模型并没有明确的指出前面列出的各种底层的执行策略具体的是被编译器、CPU、缓存控制器获取其他的机制所执行的。它甚至没有以程序员们熟悉的类、对象或方法的形式介绍过。取而代之的是,这个模型是定义了一个线程和主存之间的抽象的关系。每个线程都有一个工作内存
**working memory**(是一个缓存和寄存器的抽象概念)用来存储值。模型保证了围绕方法顺序执行交互环节的一些属性和变量的内存地址信息。大部分规则的措辞都是规定需要在什么时候应该对主内存和线程工作内存进行交换操作,这些规则产生了以下的一些交织的问题:- 原子性,这条说明需要有不可分割的效果,为达到模型的要求,这些规则只应该对相应的实例变量、实例、静态变量、数组元素(不包括方法本地变量)的简单的读和写适用。
- 可见性,在什么条件下一个线程的效果对其他的线程是可见的。这些效果包含:对一个实例变量的写入被另外一个线程的读取操作
看见。 - 顺序性,在什么情况下代码的执行顺序对任意的一个线程来说是乱序的。主要的顺序性问题是发生在读取和写入一些关联的顺序的执行一些赋值语句的变量的时候。
如果是使用同步,所有这些属性都都有一个简单的角色。在一个同步方法或者块内的所有的更新对其 他的持有同一个锁的同步方法和同步块都是原子的和可见的。并且任何线程内的同步方法和同步块的 执行都是顺序的。尽管程序块内的语句执行有可能是乱序的,但是这个对其他的使用同步的线程来说 不会有影响。
- 当程序未使用同步或者同步不一致

